Property-based testing
With examples in TypeScript, C#, and Scala

If you’ve got a couple of white hairs on the head (or beard) like I do, you might remember when writing tests was considered a waste of time. Your manager might have challenged you: “What, you’re going to write code to verify that you’re doing a good job?”. The industry has evolved, however, and realized that investments in coverage pay off in the end. Fortunately for software quality, writing automated tests has become a widely accepted and common practice.
There has also been an evolution in the technological space with more demanding users. Digital systems are so pervasive that consumers of these services expect a flawless experience. Similar to what has happened with electricity networks, downtimes have become unacceptable. Apps are so embedded in our daily lives that software disruptions have major impacts.
The evolution of software testing
Software testing is an engineering discipline in its own right. Still, the widespread cultural evolution that testing forms an integral part of coding has led to software engineers having to master both the art of creating systems and testing them. Modern software teams are fully responsible for the entire lifetime of their code, from ideation to development and testing, knowledge sharing, ensuring smooth evolution and scaling, deployment, and troubleshooting.
At first sight, the software engineer might regard testing as a boring task, a necessary evil. But today I’d like to highlight that testing tools have evolved: new and powerful testing paradigms have become accessible. These new approaches can make testing a more fun and rewarding exercise. Not only that, but such practices lead to deeper coverage and improved code clarity.
What is code, exactly?
Code is all about controlling the flow of operations acting on data. Programming languages offer us higher-level constructs such as functions and classes to manage this complexity. This makes it possible to break down a program into understandable logic blocks. This decomposed structure is also the skeleton for test coverage. We speak of unit coverage when writing a test for a single brick in isolation, and component coverage for verification of the assembly.
Creating a test involves defining imaginary data, stimulating the constructs with this input, and verifying the result. In other words, the typical unit or component test is sampling the space of possible inputs to the process under test. Crafting a good test is about figuring out what those samples should be to make the verification as exhaustive as possible.
Function domains
We can think of a software function as a mathematical function, where parameter types define the dimensions for the space of possible inputs. Tests verify some points in this space. To illustrate this mental model, let’s take a simple function computing instantaneous velocity:
function speedKmh(meters: number, seconds: number): number {
return meters / seconds * 3.6;
}Let’s say our test suite samples three input values:
describe('speedKmh', () => {
test('calculates speed as 36 km/h for inputs (1 meter, 0.1 seconds)', () => {
expect(speedKmh(1, 0.1)).toBe(36);
});
test('calculates speed as 72 km/h for inputs (2 meters, 0.1 seconds)', () => {
expect(speedKmh(2, 0.1)).toBe(72);
});
test('calculates speed as 120 km/h for inputs (30 meters, 0.9 seconds)', () => {
expect(speedKmh(30, 0.9)).toBe(120);
});
});We can represent this visually with a 3D plot:
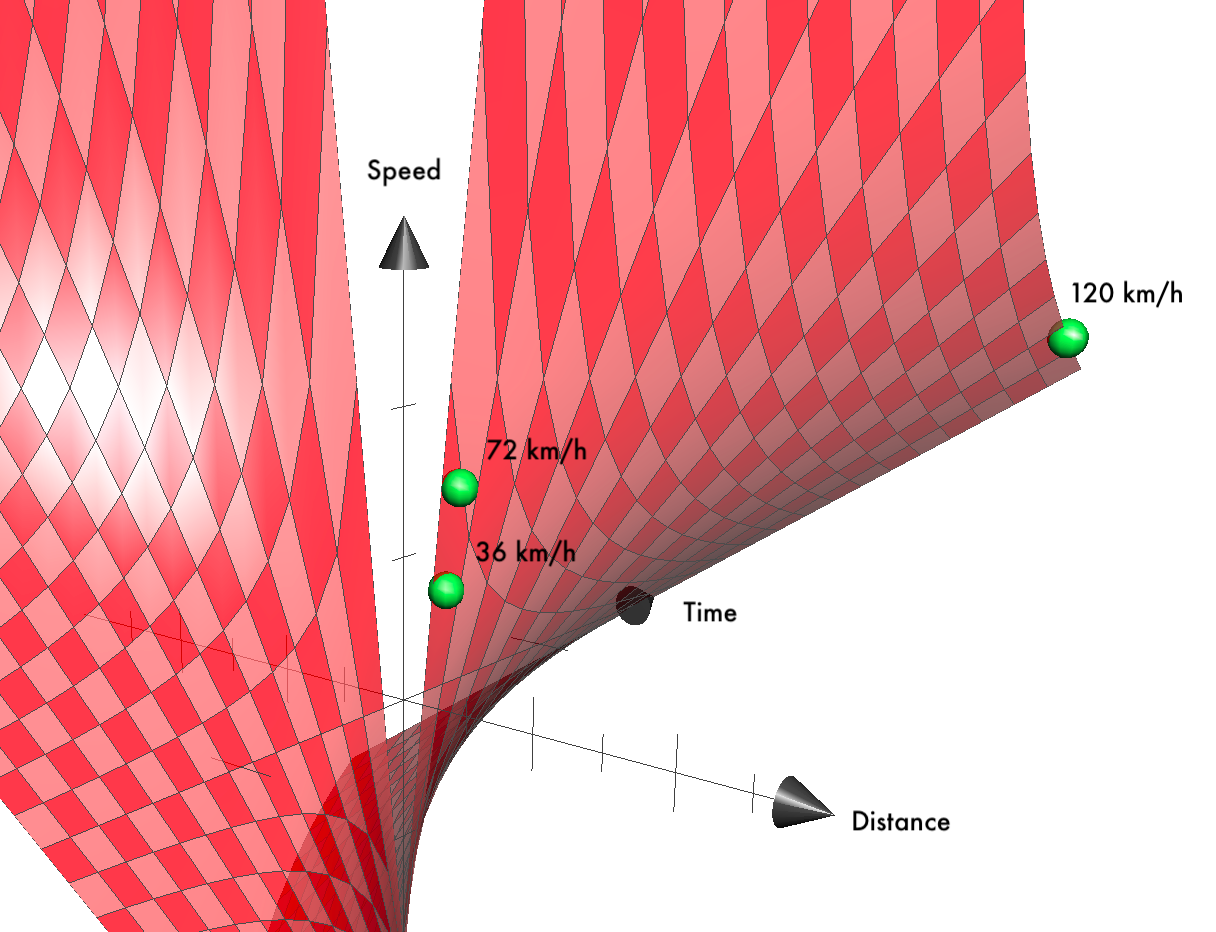
When hand-picking fixture (i.e. setup) values, it’s easy to miss important inflection points or areas of function space that we didn’t think of. In this simplistic test suite, we assumed that the time parameter would never be zero (that would result in an exception). We also overlooked that our function allowed for negative values (which most likely wasn’t our intention).
Unfortunately, predicting all possible combinations of input values and states in a software system is generally very hard or even impossible. Bugs often reside in such unexplored and undefined execution flows.
“Properties” of a piece of code
In addition to a limited set of verifiable input/output pairs, it’s often possible to find higher-level properties that are code invariants. In this trivial example, we can formulate that speed has the “property” of always being defined and positive. Here’s how to translate this into code in TypeScript using fast-check:
import fc from 'fast-check';
describe('speed', () => {
it("is always defined and positive", () => {
fc.assert(
fc.property( // this is the property definition
fc.integer(), // meters explored with the full range of integers
fc.float(), // same for seconds, with floats
(meters, seconds) => {
const result = speedKmh(meters, seconds);
expect(result).toBeDefined();
expect(result).toBeGreaterThanOrEqual(0);
}
));
})
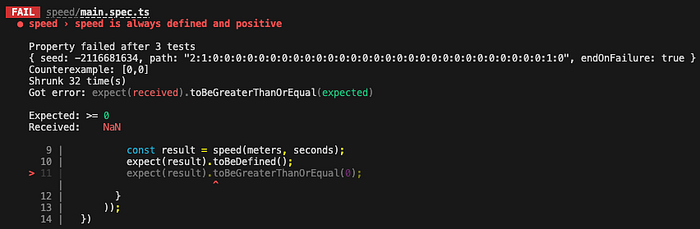
});Fast-check runs the test multiple times by picking random input values, with a bias for special values such as zero or infinite. When a failure is detected, the input is “shrunk” to simplify the case to its minimal form while still causing the failure. For example, if a property-based test generates a large array of numbers that causes a failure, the shrinker will try to reduce the array size or simplify the values until it finds the smallest failing case.
Evaluation of our example reveals a problem with the implementation, and after shrinking fast-check deduces that meters=0, seconds=0 invalidates the property:
If we correct the function logic to return zero when speed is either negative or undefined:
export function speedKmh(meters: number, seconds: number): number {
if (seconds === 0) return 0;
if (seconds < 0 || meters < 0) return 0;
return (meters / seconds) * 3.6;
}Our property is now verified:

Narrowing the types
Thinking in terms of properties forces us to reflect on the input domain of our code. There are only two options to ensure safety: we can account for degraded values like we did above, or restrict the input space, by taking advantage of the type system.
For the above example in TypeScript, we can make use of a nifty type refinement idiom to improve the type precision of our function:
const M = Symbol();
export type Nominal<Name extends string, Type> = Type & {
readonly [M]: [Name];
};
type Meters = Nominal<'Meters', number>;
type Seconds = Nominal<'Seconds', number>;
type Kmh = Nominal<'Speed', number>;
export function meters(meters: number): Meters {
if (meters < 0) throw new Error('Meters must be non-negative');
return meters as Meters;
}
export function seconds(seconds: number): Seconds {
if (seconds <= 0) throw new Error('Seconds must be positive');
return seconds as Seconds;
}
export function kmh(kmh: number): Kmh {
if (kmh < 0) throw new Error('Speed must be non-negative');
return kmh as Kmh;
}
export function speed(meters: Meters, seconds: Seconds): Kmh {
return kmh((meters / seconds) * 3.6);
}The idea is to delegate verification of input soundness to the caller of speed. Adopting this philosophy throughout the codebase will propagate data soundness concerns to parsing and input layers at the edges of the application while increasing the precision of our business logic.
We must also adapt our property and define specific data generators for refinement types. map and filter operators let us transform the original value range to what we need:
const metersGen = fc.integer().map(m => meters(Math.abs(m)));
const secondsGen = fc.float().filter(s => s > 0).map(s => seconds(s));
describe('speed', () => {
it("speed is always defined and positive", () => {
fc.assert(
fc.property(metersGen, secondsGen,
(meters, seconds) => {
const result = speed(meters, seconds);
expect(result).toBeDefined();
expect(result).toBeGreaterThanOrEqual(0);
}
));
})
});Documentation and decoupling
We have seen above how sampling the input only partially covers the code. The same argument can be made for the associated semantics. Fixtures often mix values relevant to the system under test with secondary values uniquely needed to call the function or instantiate the class. The outcome is similar to what makes magic numbers an anti-pattern.
Newcomers to the codebase will have difficulty identifying the role of particular sample values and the impacts of changing fixtures. When extending the coverage or modifying the application code, the easiest is to copy the full fixture, leading to growing repetition. This, in turn, harms the resilience of coverage code to evolutions.
A trivial C# example illustrates this idea using FsCheck and xUnit. We define a User record with a computed property AgeGroup :
public enum AgeGroup { Child, Teenager, Adult, Senior }
public record User(string FirstName, string LastName, int Age)
{
public AgeGroup AgeGroup
{
get
{
if (Age < 13)
{
return AgeGroup.Child;
}
else if (Age >= 13 && Age < 20)
{
return AgeGroup.Teenager;
}
else if (Age >= 20 && Age < 65)
{
return AgeGroup.Adult;
}
else
{
return AgeGroup.Senior;
}
}
}
}A property of age group logic is that the full range should be represented for a sufficiently large population:
[Property]
public void AllAgeGroupsRepresented() {
Prop.ForAll(
Gen.ArrayOf(Gen.Choose(0, 110), 1000).ToArbitrary(),
ArbMap.Default.ArbFor<string>(),
ArbMap.Default.ArbFor<string>(),
(ages, arbitraryFirstName, arbitraryLastName) => {
var users = ages.Select(age =>
new User(arbitraryFirstName, arbitraryLastName, age));
Assert.Equal(4, users.Select(user => user.AgeGroup).Distinct().Count());
})
.QuickCheckThrowOnFailure();
}Notice how we avoided using specific values for names such as “John Doe”. Names are naturally irrelevant to this test, but often with real data types and complex logic, figuring out what’s relevant to the test from what’s just needed to arrange the fixture isn’t so obvious.
Other typical use cases
Round-trip tests
A great use case for data space exploration is ”round-trip” testing for mapping or transformation code. Here’s an example in C# with Automapper: we define a Vehicle class and a VehicleDTO record, with an Automapper profile. The property verifies that we can convert an instance of the class to the DTO and back and that values are the same, for any vehicle (FsCheck can auto-generate instances of Vehicle):
public class Vehicle
{
public required int Id { get; init; }
public required string Model { get; init; }
public string? Make { get; set; }
public int? Year { get; set; }
}
public record VehicleDTO(int Id, string? Model, string? Make, int? Year);
public class VehicleProfile : Profile
{
public VehicleProfile()
{
CreateMap<Vehicle, VehicleDTO>().ReverseMap();
}
}
public class VehicleMappingTests
{
private readonly IMapper mapper;
public VehicleMappingTests()
{
var config = new MapperConfiguration(cfg => cfg.AddProfile<VehicleProfile>());
mapper = config.CreateMapper();
}
[Property]
public void VehicleToDTORoundTripMapping_ShouldBeSuccessful(Vehicle vehicle)
{
var vehicleDto = mapper.Map<VehicleDTO>(vehicle);
var mappedBackVehicle = mapper.Map<Vehicle>(vehicleDto);
vehicle.Should().BeEquivalentTo(mappedBackVehicle);
}
}Law testing
Functional programming embraces high-level algebraic constructs that abide by mathematical laws. One useful type class is Monoid, which defines a set equipped with an associative binary operation and an identity element. Property testing makes it possible to verify these laws for a certain type.
One type that often appears when building distributed systems is the hashmap. With the map-reduce pattern, the coordinator distributes elements by key across the cluster for parallel processing and recombines the computed values. As an example, let’s imagine a dataset of scores per player, expressed in Scala:
@main
def demo(): Unit =
val sessions = List(
Map("Alice" -> List(1)),
Map("Bob" -> List(2)),
Map("Alice" -> List(3)),
Map("Alice" -> List(4)),
Map("Alfred" -> List(2, 5)),
Map("Bob" -> List(6)),
Map("Alfred" -> List(7)))
sessions.combineAll.map { case (name, values) =>
name -> values.sorted
} foreach println Running this small program leads to the following output:
(Alice, List(1, 3, 4))
(Bob, List(2, 6))
(Alfred, List(2, 5, 7))The “magic” that makes this possible is the following Monoid definition, picked up by combineAll implicitly to traverse sessions and merge lists for each key:
given mapMonoid[K, V: Monoid]: Monoid[Map[K, V]] with
def combine(a: Map[K, V], b: Map[K, V]): Map[K, V] =
(a.keys ++ b.keys).map { key =>
key -> (a.getOrElse(key, Monoid[V].empty) |+| b.getOrElse(key, Monoid[V].empty))
}.toMap
def empty: Map[K, V] = Map.empty[K, V]Note that this definition delegates value combination to its own Monoid instance (listMonoid in the present case, not illustrated here).
Tests validate the Monoid laws with properties. We can use any value type if a Monoid exists for the type. For the tests, we use Int values for simplicity (the standard Monoid for Int is sum):
object MapMonoidTests extends Properties("Map Monoid"):
property("associativity") = forAll { (a: Map[String, Int], b: Map[String, Int], c: Map[String, Int]) =>
((a |+| b) |+| c) == (a |+| (b |+| c))
}
property("identity") = forAll { (m: Map[String, Int]) =>
(m |+| Monoid[Map[String, Int]].empty) == m && (Monoid[Map[String, Int]].empty |+| m) == m
}In summary
Property testing is an approach to software testing that complements traditional example-based testing. Focusing on properties rather than specific cases ensures code behaves correctly across all possible inputs. Highlighting flaws in input space coverage, properties impose a discipline of thorough behavior description. This, in turn, encourages type narrowing, leading to increased precision in business logic, and decoupling of concerns.
